
使用开源的自然语言处理NLP和向量数据库Faiss实现一个检索式智能客服
前言
本篇文章最后会给出一个最快速不需要编码的解决方案。
在怎么实现一个智能客服一文中,已经大致的介绍了实现一个智能客服的思路。需求的整个流工作程,如下:
- 管理员录入问题
- 用户提出问题
- 服务端返回相似问题或做出回答
- 用户选择服务端返回的对应的问题
- 服务端做出回答
接下来我这里大致讲一下具体的实现中的核心的问题,让我们带着这两个问题往下读:
- 系统是怎样的一个结构?
- 怎么实现文本识别和题干搜索?
题干搜索
题干搜索一共有以下几种方式:
- 基于关键词的匹配:可以提取问题中的关键词,然后在问答库中查找包含这些关键词的问题。这种方法简单易实现,但可能无法处理复杂的问题。
- 基于向量空间模型的匹配:可以将问题和问答库中的问题都转换为向量,然后计算问题向量之间的相似度。可以使用 TF-IDF、word2vec、BERT 等方法来将问题转换为向量。这种方法可以处理更复杂的问题,但需要更多的计算资源。
- 基于深度学习的匹配:可以使用深度学习模型来匹配问题。例如,可以使用 Siamese 网络或 Transformer 网络来计算问题之间的相似度。这种方法可以获得最好的匹配效果,但需要大量的数据和计算资源。
我们不采用第一种和第三种方式。因为第一种方式检索准确的不够;第三种方式有点杀鸡用屠龙刀的感觉,并且我也不会^~^。
模型概念介绍
但不代表第三种方式是一个触不可及的东西,所有的机器学习模型,不管是决策树神经网络等等,都是有写好的开源库,举例:开发者只需要将数据分类喂养给这些模型,所有的模型都是数学上的一个方程式,比如:y=XW+b,模型的训练就是确定 W 和 B 的一个过程。scikit-learn 是一个用于模型训练的一个库,内部实现了数学家提出的多种算法。
举例说明:
场景:系统有大量已处理的用户欠款数据,并标记了是否已经还款,还款的额度是多少,我们需要预测未处理用户数据是否会还款,并且还款比例是多少?
- 我们可以使用决策树的模型或者神经网络的模型中的分类去预测
未处理用户是否会还款,模型训练的过程是确定方程式的一个过程,比如方程式是:y=ax+b,x 是自变量(需要处理的用户信息),y 是因变量(该用户的分类,是否会还款),a 和 b 是常量(是模型在训练中根据数据确定的一个过程),当然方程式不会这么简单,一旦方程式中的值确定后,模型就训练完成了,模型训练完成后就会得到一系列的参数,使用模型的过程就是将数据放入表达式的一个过程。 - 我们可以使用决策树的模型或者神经网络的模型中的回归去预测
未处理用户会还款的金额,回归简单来说就是预测函数中的下一个点,比如股票的走势预存等。
上述的表达中,只是冰山一角吧,作者也不是做模型训练的,只是让外行人能够理解它,不要惧怕它,觉得它高大上等。在实际的工作中,都需要根据响应速度、准确度等要求,靠经验去决定使用那种模型。作者也不会做模型训练,但是当我理解了上述概念后,如果工作中有需求做模型训练,以 GPT4 和长期的开发经验的加持下也不是什么难事儿。
总结来说,模型就是数学家提出来的方程式,训练模型得到一推参数的过程是确定方程式常量的一个过程,模型是否准确和喂养模型数据有关系也和开发者采用的方法有关系,最终为了得到 y 值可以是任何想要的数据。
scikit-learn

NLP 自然语言的量化实现
回归正题,我采用第二种方式实现问题题干的匹配。首先我们需要使用 NLP 对应的一些开源库,比如:spacy 、jieba ,还需要使用 scikit-learn 库中的余弦相似度方法比较两个是否相同。
代码实现
项目地址 https://github.com/Lands-1203/NLPTest
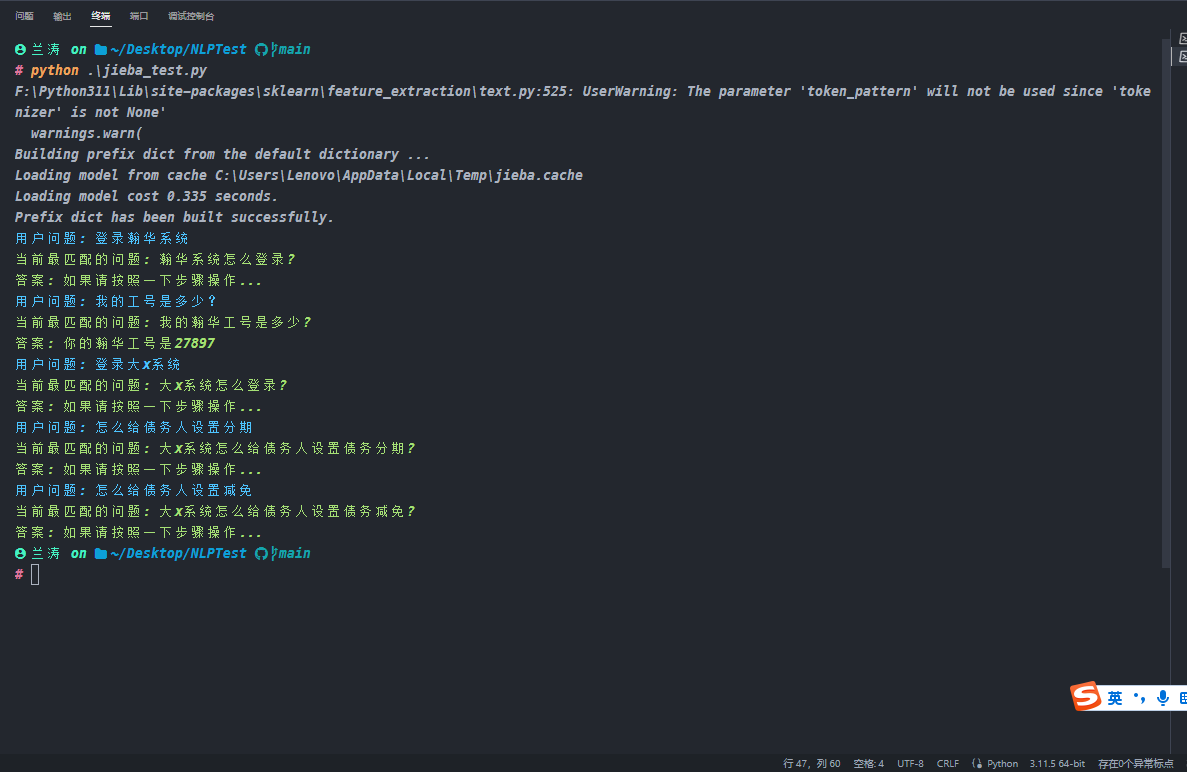
1 | import jieba |
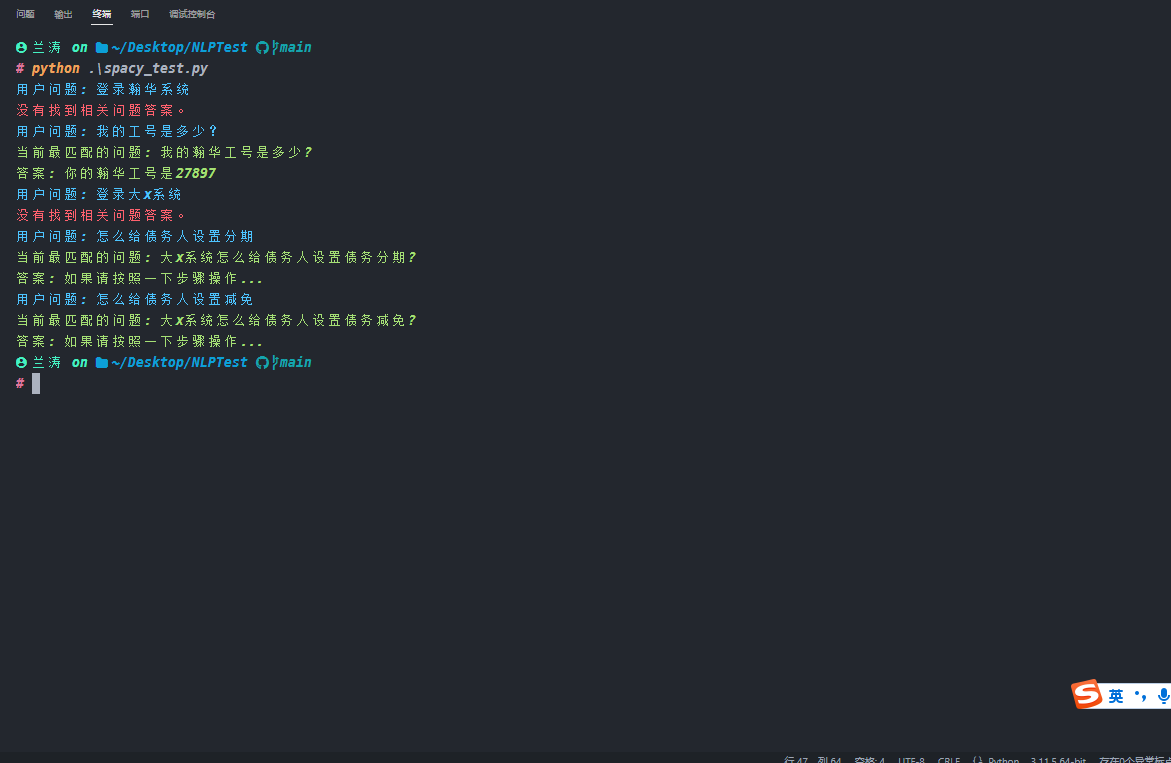
1 | import spacy |
总结整理
在上述运行结果中,我们可以看到spacy 没有jieba 准确,spacy 也可能是更好的使用方式。不管使用哪个包,我们都是一个思路将提问的问题转换成向量进行相似度对比。
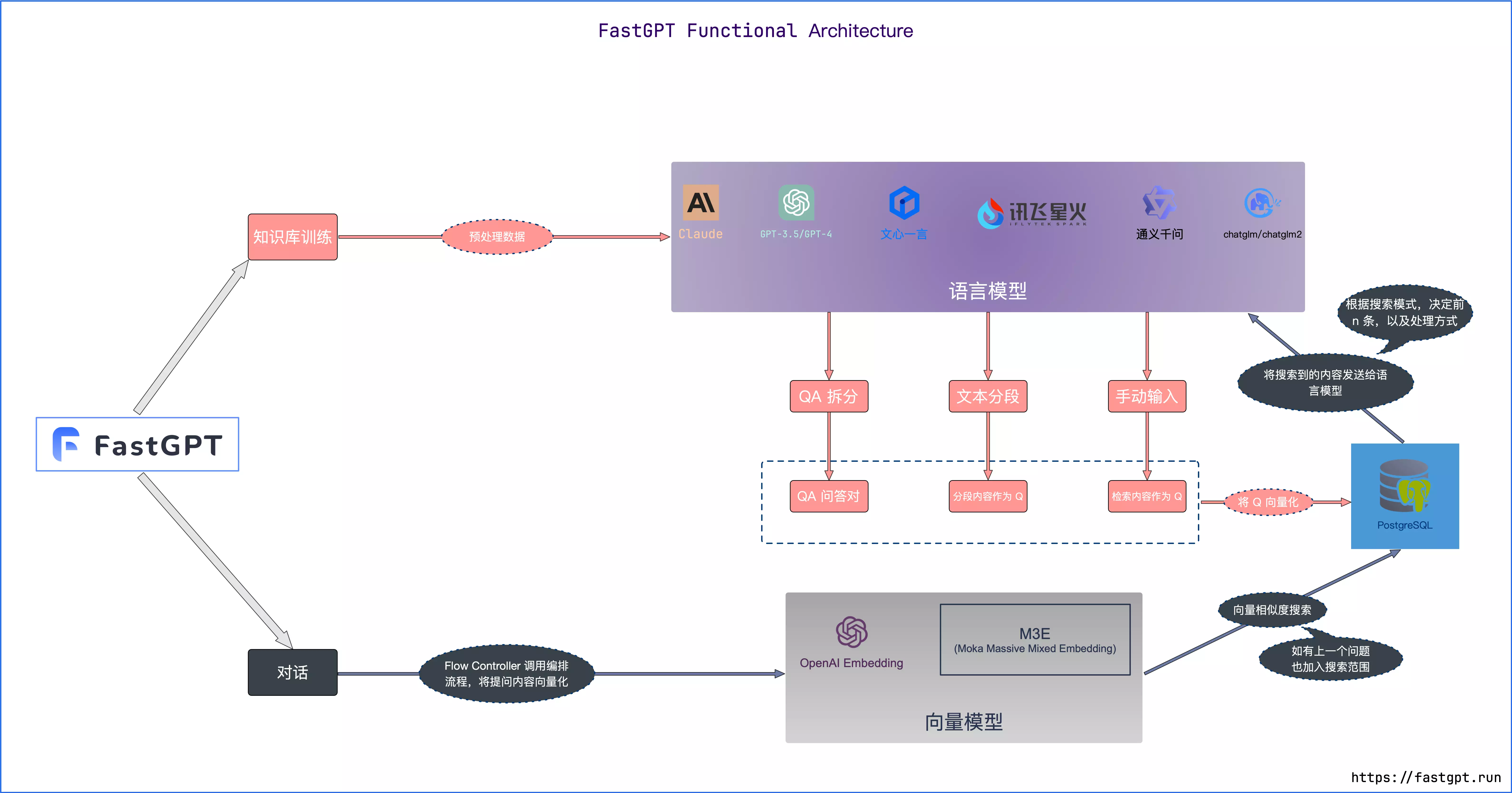
下图来自于 FastGPT

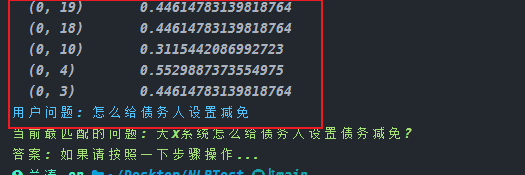
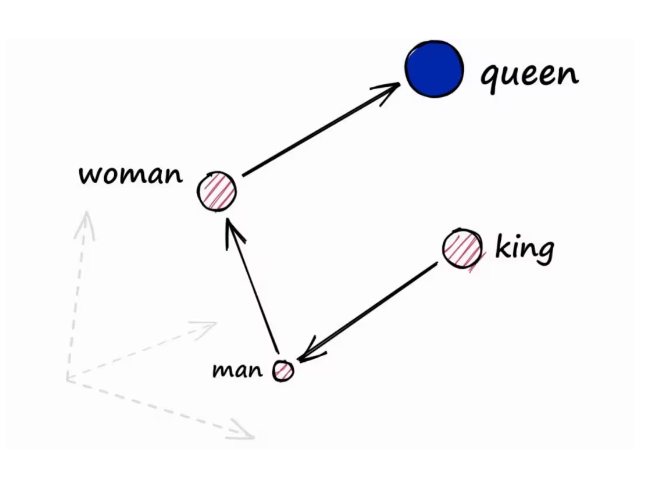
对比的方法是使用的余弦相似度对比,这个方法很常用,比如可以使用它将图片灰度后将像素点转换成 0 1 hash 值进行相似度对比,他的原理就一个具象化的过程。在这里他是将自然语言转换成为一个多维向量,再将两个向量进行相似度对比,比如说是一个在 x 和 Y 轴上的两个二维的向量,那余弦相似度对比就是比较这两个向量的斜率。当然在实际中,他可能是一个几十维的向量。如下图:
下图来源于哔哩哔哩的向量介绍
在进行相似度对比的时候,如果题库量不是特别大,我们可以在添加问题的时候记录下问题的向量值,用户提问的时候将用户和已保存的向量值进行相似度对比,再输出答案或者问题组供用户选择。但在问题量比较大的时候,如果用户在提问的时候,我们再将所有问题拿出来进行对比返回,就是一个比较消耗内存和 CPU 的过程,所以我们需要使用到向量数据库 Faiss。
Faiss 介绍
Faiss 是一个由 Facebook AI Research (FAIR) 团队开发的库,专门用于高效的相似性搜索和密集向量聚类。它能够处理从几千到数十亿规模的向量集合,并提供了丰富的接口来进行向量之间的快速搜索操作。Faiss 非常适合于那些需要进行大规模向量搜索的应用场景,比如推荐系统、图像检索、自然语言处理中的相似文档查找等。
核心特性
- 高效的搜索性能:Faiss 使用了先进的索引结构和优化算法,能够在大规模数据集上实现快速的相似性搜索。
- 支持多种索引类型:包括扁平索引(暴力搜索)、倒排索引、量化索引等,用户可以根据具体需求选择合适的索引类型。
- 支持 GPU 加速:Faiss 提供了对 GPU 的支持,可以显著提高搜索速度和索引构建速度。
- 易于使用的 API:提供了 Python 和 C++ 的 API,方便集成到现有的应用中。
使用场景
- 向量相似性搜索:在大规模向量数据库中快速找到与查询向量最相似的向量。
- 聚类:对大规模向量数据集进行聚类操作,以发现数据的潜在结构。
- 去重:在向量数据集中找到并去除重复或非常相似的项。
如何使用
使用 Faiss 进行相似性搜索通常包括以下步骤:
- 选择或构建索引:根据数据规模和搜索需求选择合适的索引类型。
- 向索引中添加向量:将数据集中的向量添加到索引中。
- 执行搜索操作:对于给定的查询向量,执行搜索操作以找到最相似的向量。
示例代码
以下是一个简单的 Python 示例,展示了如何使用 Faiss 进行向量搜索:
1 | import faiss # 导入faiss库 |
faiss 相关的教程(未经验证,需谨慎):
FAISS 教程
Meta 向量数据库 Faiss 介绍
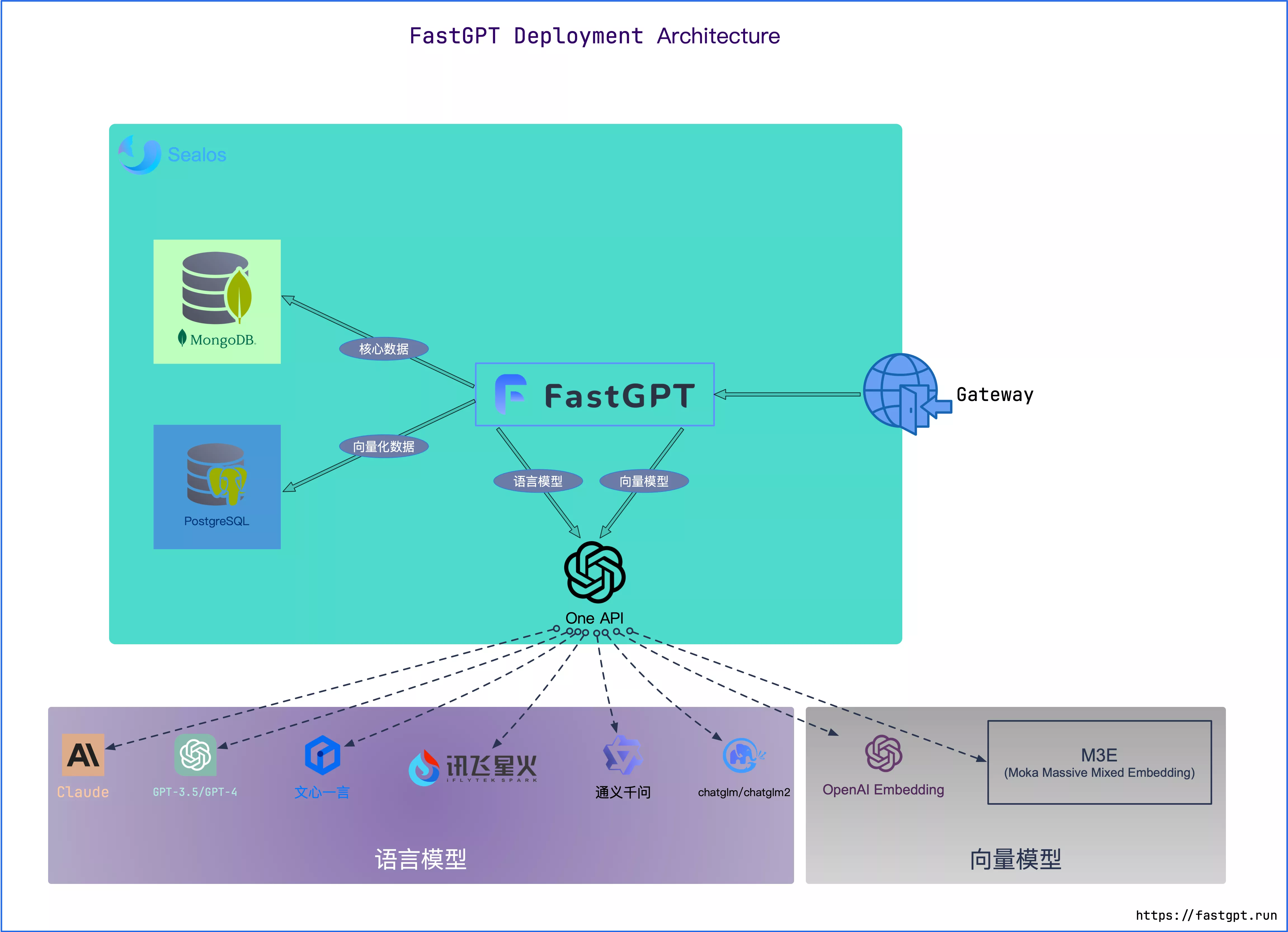
系统架构
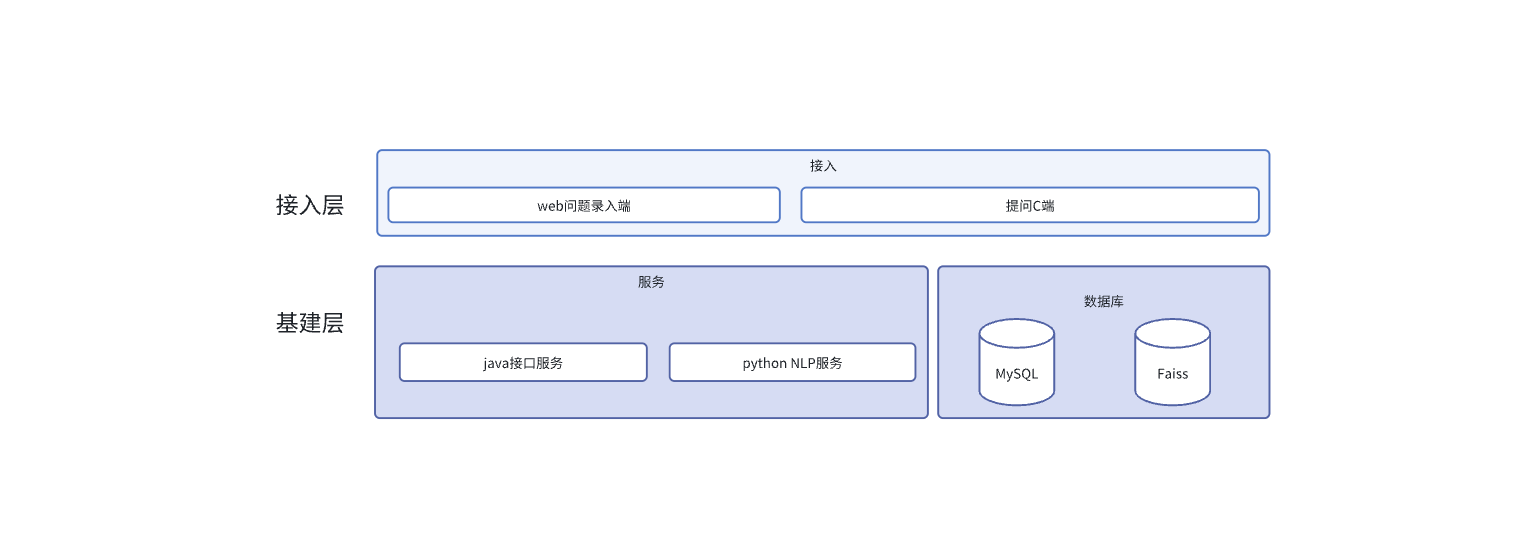
如上图,我们需要搭建两端的平台,web 端与交互 C 端,其中交互 C 端可以借助在任何三方应用上(微信、企微、钉钉、飞书)。在 WEB 端服务中,Java 服务承接用户提问或者管理员创建的接口,Python 服务由 Java 服务调用,进行向量生成与存储、向量相似度查询等操作,python 返回唯一标识。在服务器端,mysql 存储问题相关信息,faiss 储存向量和负责搜索向量。整体流程如下:
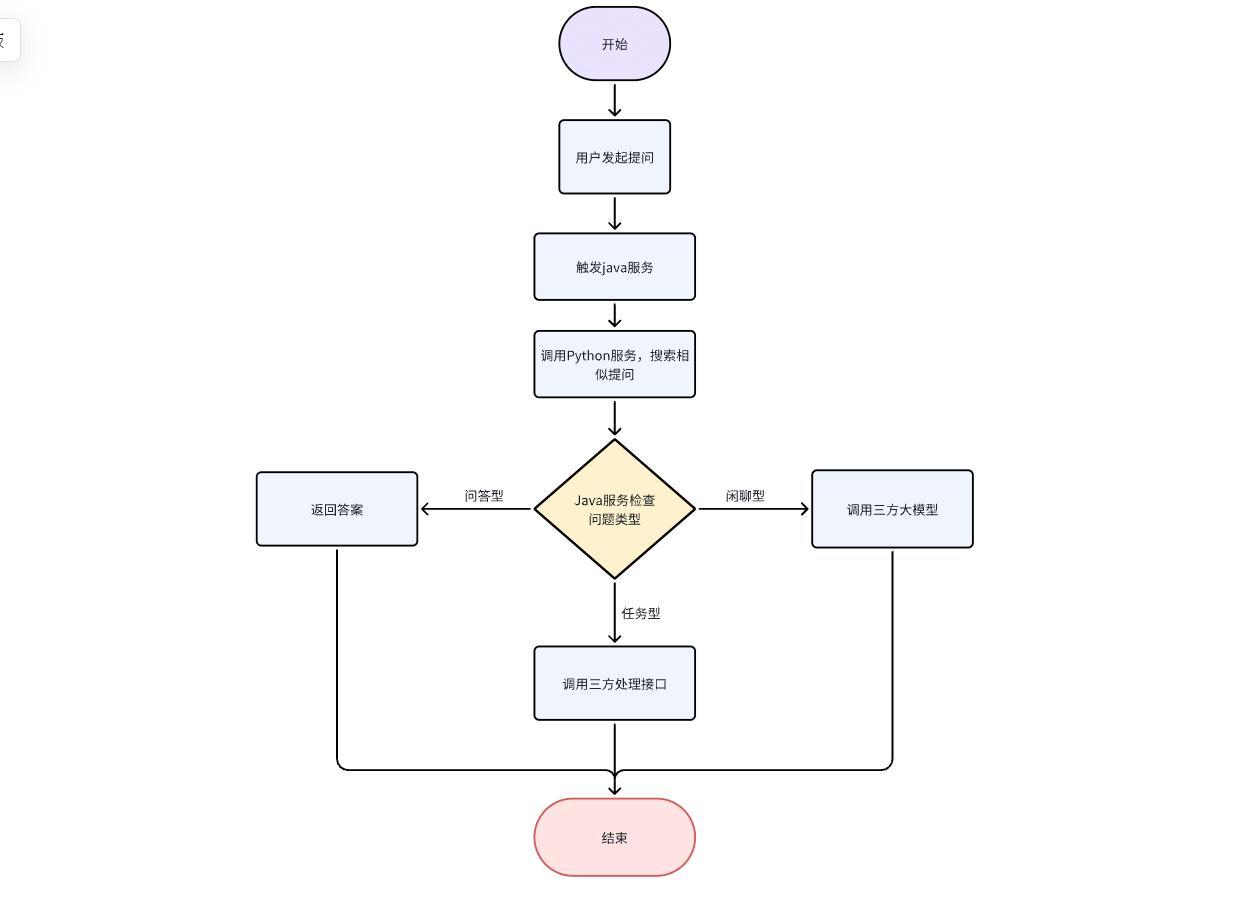
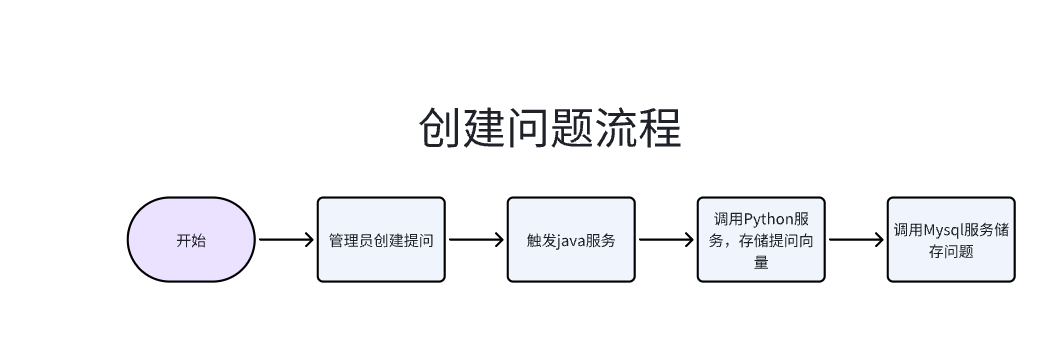
WEB 端设计
在 web 端的开发中,对于该需求本身我们只需要提供一类接口,问题的增删改查
| 接口名 | 请求字段 | 返回字段 |
|---|---|---|
| 问题分页列表 | 略 | 略 |
| 问题新增接口 | 提问请求字段 | 略 |
| 问题编辑接口 | 提问请求字段 | 略 |
| 问题删除接口 | 略 | 略 |
问题类型分为闲聊型、任务型、问答型,其中:
- 问答型:管理员后台录入标准答案,用户命中对应的提问后,返回录入的答案
- 任务型:管理员后台录入回答时触发的接口,用户命中对应的提问后,返回接口返回的答案
- 闲聊型:管理员录入触发关键字或者提问方式,用户命中后,将提问数据提交到三方大模型(比如 GPT、百度模型、讯飞模型等),将大模型返回的答案添加上来源标识,让用户明确回答并非来源于系统回答
闲聊型是一种特殊的任务型提问,在触发某种条件后自动接入三方的大模型,让大模型给予用户回复。
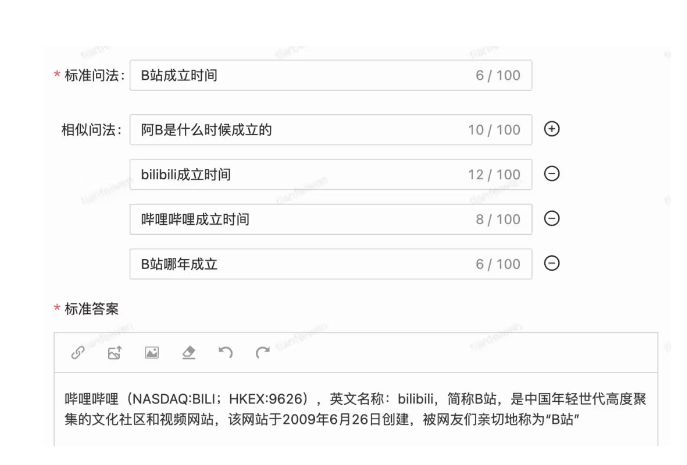
在数据库中,录入标准提问、相似提问、答案,录入的方式有很多种,最终肯定都是以 web 前端为承接方式。
提问请求字段
1 | { |

C 端设计
略
总结
整个智能客服的建设过程就在次完结了,但是我接下来还会介绍一些开源项目,能够帮助我们快速建设起公司自己的知识库,不需要编码。
使用开源项目快速搭建问答系统
FastGPT
Langchain
上述两个开源项目无需编码就能够快速搭建起一套问答系统,支持上传图片、PDF、word 等等资源上传作为知识库。这两个项目只是一个问答系统的框,在内部可以指定向量数据库、语言模型(GPT、智谱 AI 、百度模型等)。
相关资料汇总
https://github.com/labring/FastGPT FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
https://github.com/chatchat-space/Langchain-Chatchat 基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
https://ollama.com/download/windows 在本地启动并运行大型语言模型。
效果
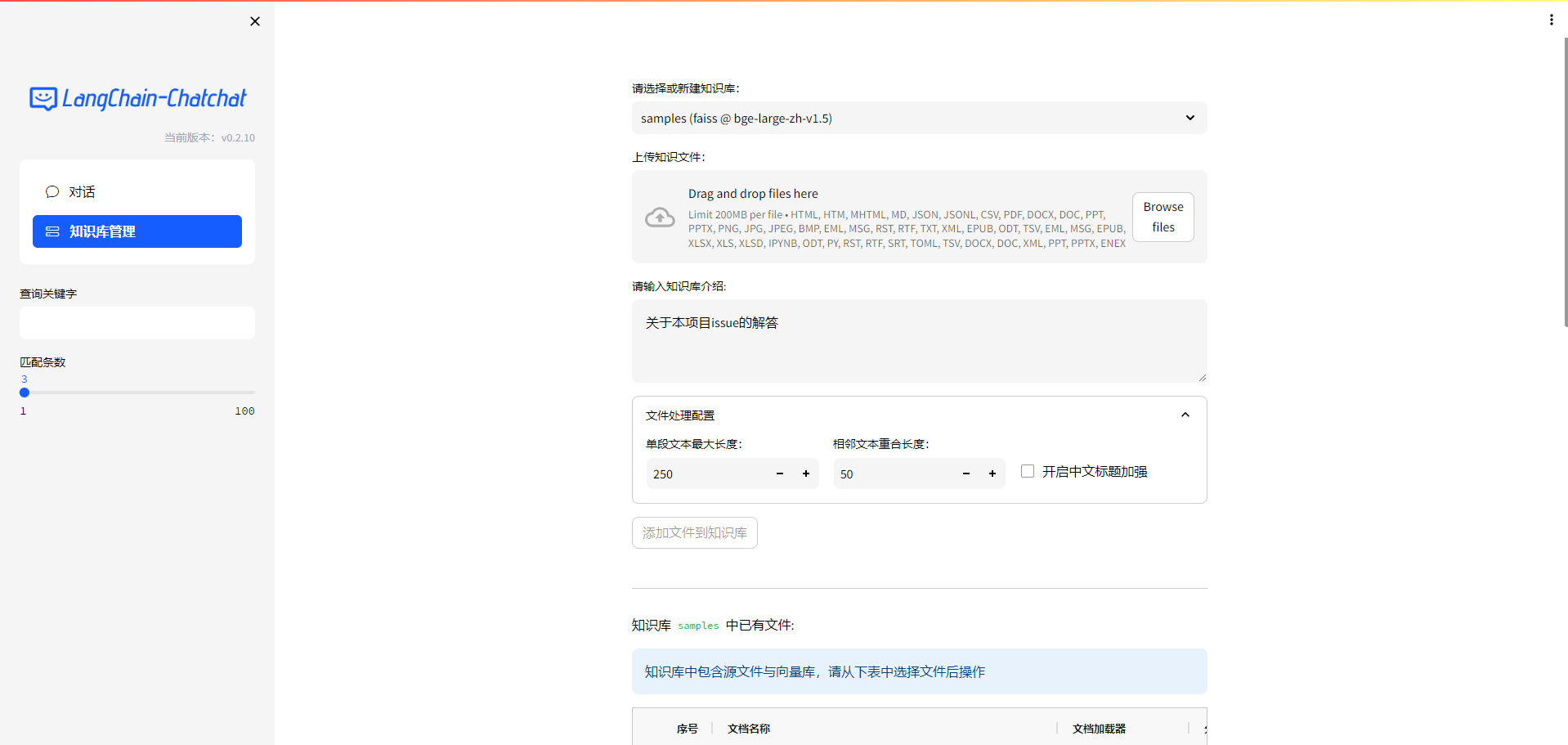
Langchain-Chatchat
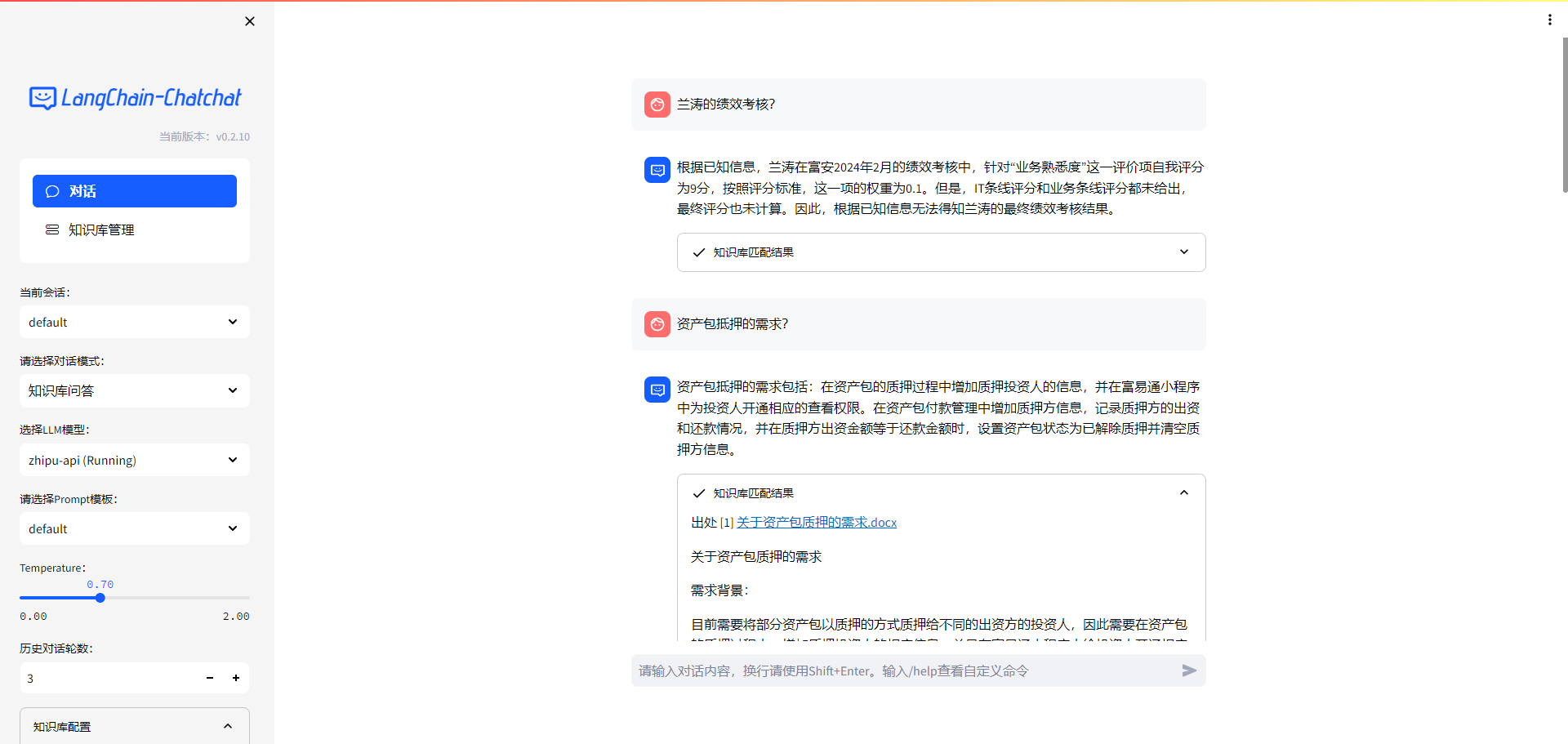
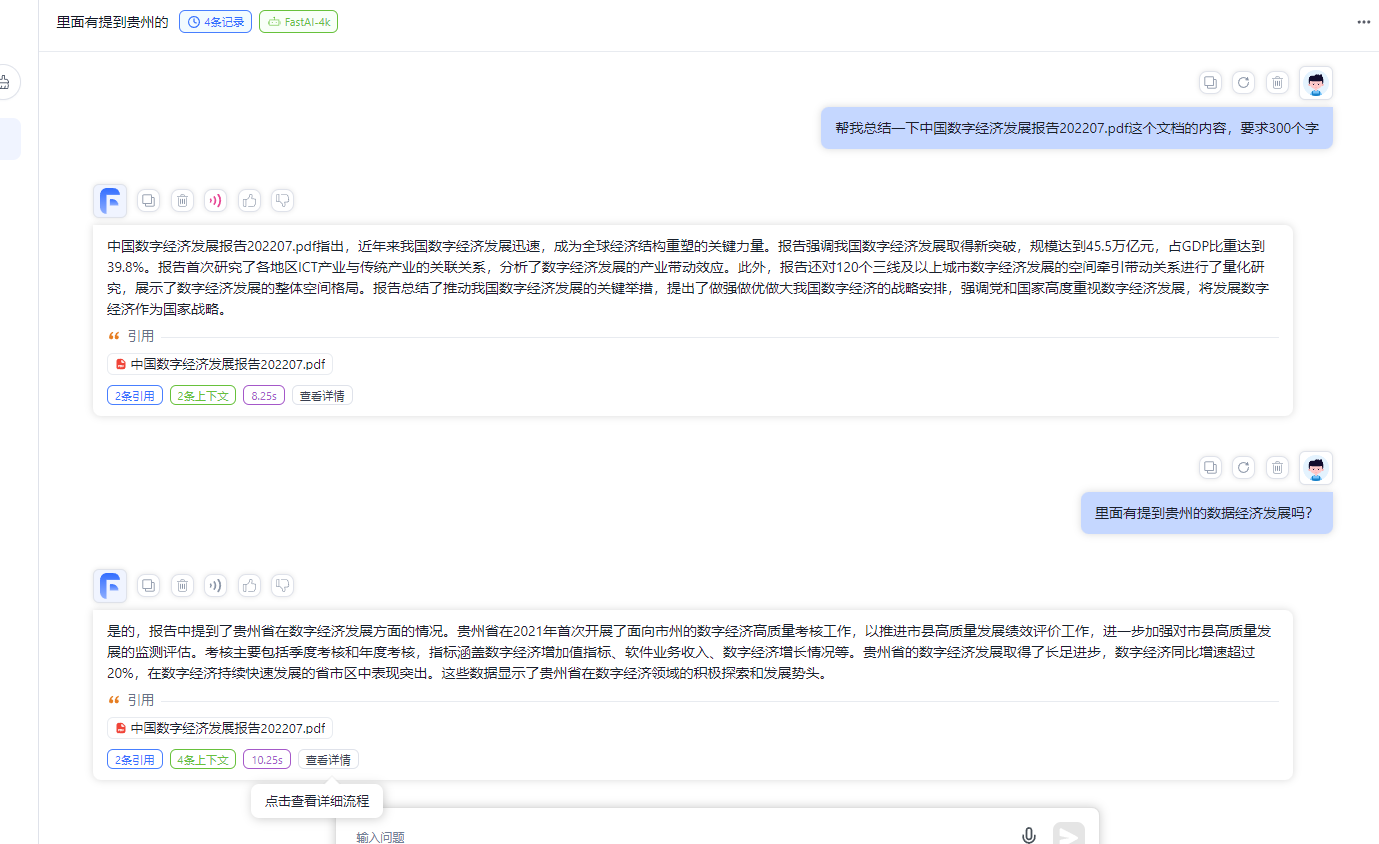
FastGPT
相关资料
- 标题: 使用开源的自然语言处理NLP和向量数据库Faiss实现一个检索式智能客服
- 作者: 兰涛
- 创建于 : 2024-03-07 14:40:26
- 更新于 : 2024-03-11 16:59:32
- 链接: https://lands.work/14ac7a18/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。