
怎么实现一个人工智能 AI 客服
前言
本篇文章是一偏思想概念接入性的文章,并不会教大家怎么去实现 AI 人工客服。只为了让各位去理解智能人工客服到底是怎么实现的?大体分为几个步骤,每个步骤中大体需要做些什么?难点是什么?(我只是一个搞前端的,对这些方面来说不是专业的,希望各位读者能多多指教)
首先机器人的问答技术大致分为两种:
- 检索式:将答案和问题事先准备好,在客户问的时候检索最接近的答案与之匹配。低复杂性
- 生成式:主要采用深度学习技术以及最新的大语言模型,通过学习大量数据来自动生成回复。高复杂性
在客服这个应用场景大多选择的是检索式,需要保证问题的准确性。
实现人工智能客服
实现一个人工智能 AI 客服,主要包含以下四个步骤:
- 定义问题和答案:首先,需要定义客服系统需要回答的问题和答案。这些问题和答案可以存储在数据库中。
- 使用自然语言处理(NLP)技术:需要使用 NLP 技术来理解用户的问题。这可能包括词性标注、命名实体识别、依存关系解析等。
- 匹配问题和答案:一旦理解了用户的问题,就需要找到最匹配的答案。这可能需要使用一些搜索算法或者机器学习算法。
- 生成回答:最后,需要生成一个回答,这可能涉及到文本生成技术。
怎么定义问题和答案?
在数据库中,录入标准提问、相似提问、答案,录入的方式有很多种,最终肯定都是以 web 前端为承接方式。
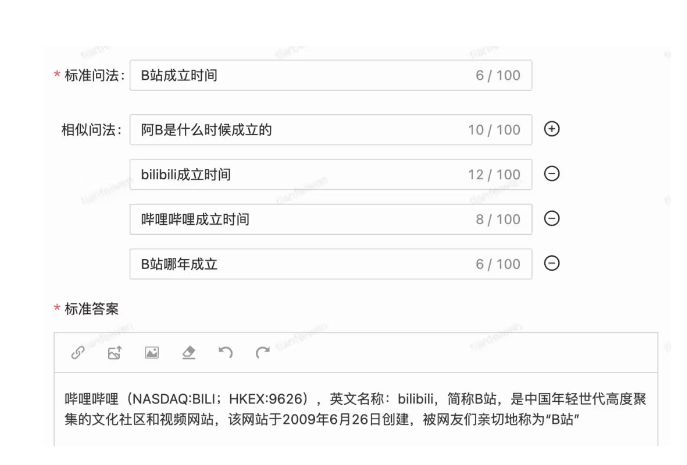

我们看到检索式问题分为两种:
- 直接是文本回答,哔哩哔哩的的这种。
- 需要动态查询的,查询送餐员电话。基于这种我想到的是,将问题的答案绑定给一个动作,这个动作就是查询当前客户的送餐员电话。当然肯定也有一个专门的动作创建页面,对许多动作进行定义
自然语言处理(NLP)技术,是什么,怎么使用?
自然语言处理(NLP)是一种人工智能技术,用于理解和生成人类语言。NLP 的主要任务包括语音识别、自然语言理解、自然语言生成和机器翻译等。
在 Python 中,有许多库可以帮助我们进行 NLP 任务,如 NLTK、spaCy、Gensim 和 Transformers 等。
以下是一个使用 spaCy 进行基本 NLP 任务的例子:
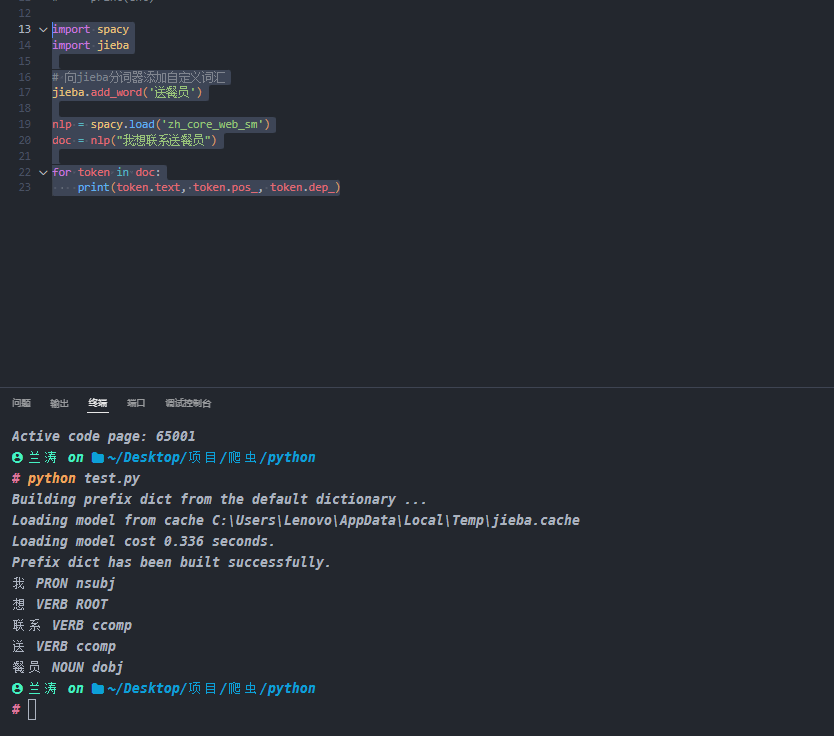
示例一:spacy 高级自然语言处理处理库
1 | import spacy |
示例二:jieba 中文处理库
1 | import jieba |
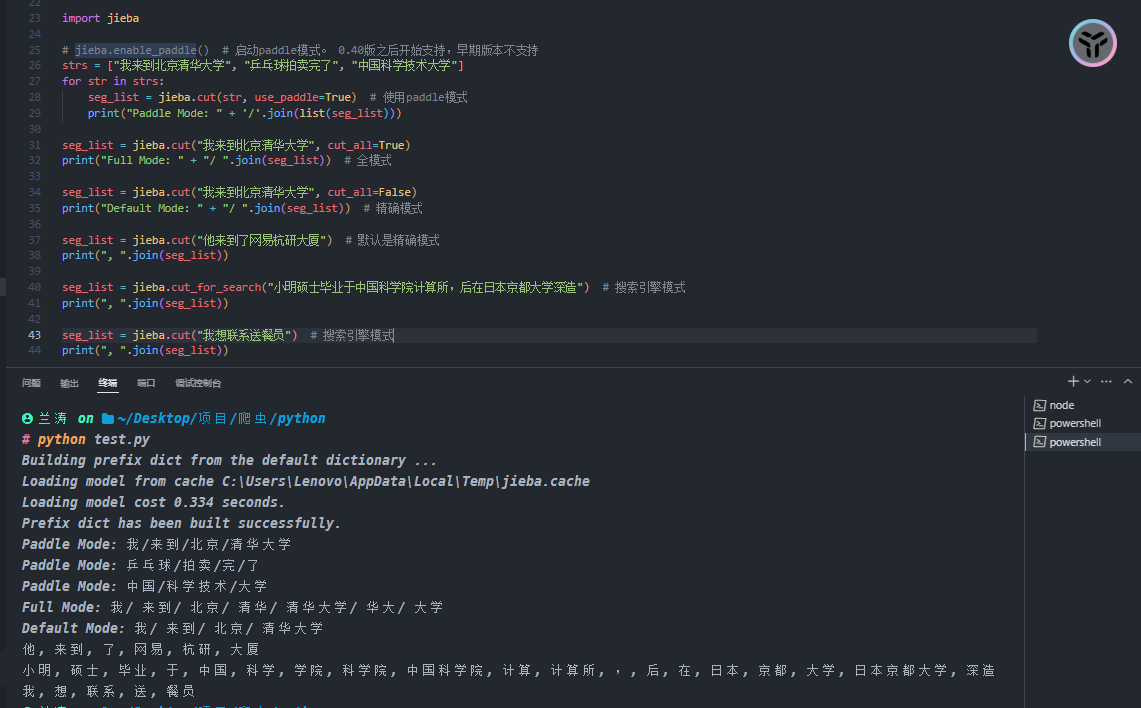
在上图中,我们可以看到这个库把许多词都分开了,比如“乒乓球拍卖完了”,分解成了【乒乓球\拍卖】,“送餐员”分解成了:【送\餐员】
示例三: 自定义词库
在 jieba 中我们,我们可以自定义词库。
1 | # encoding=utf-8 |
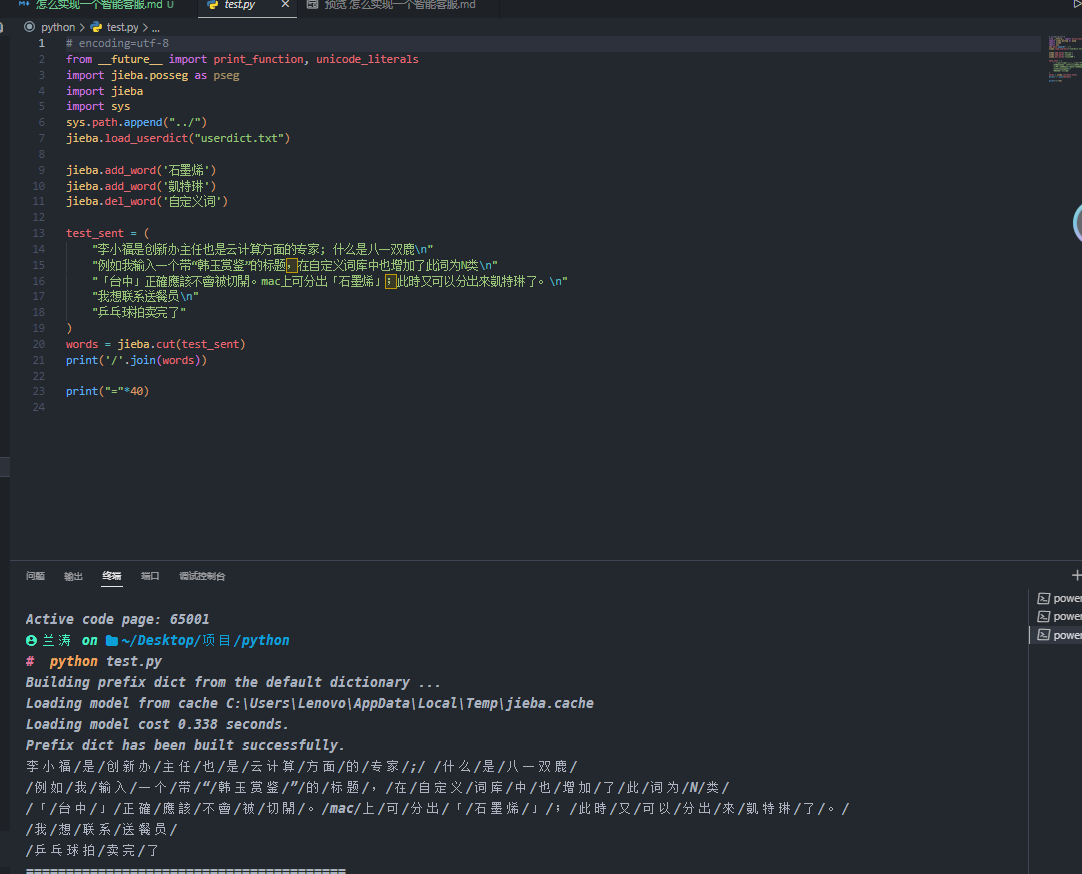
词类型对照表
1 | 云计算 5 |
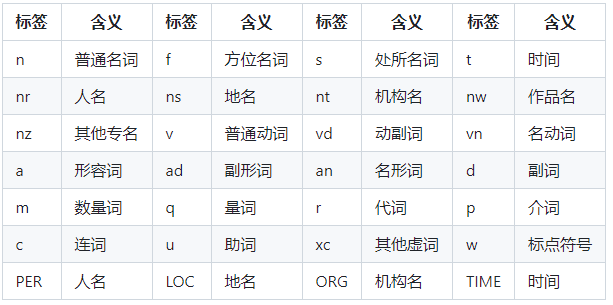
在 jieba 的自定义词典中,每一行都代表一个词条。每个词条由三部分组成:词语、词频和词性,它们之间用空格分隔。
- 词语:这是想要添加到词典中的词。
- 词频:这是词的频率,用于调整词的切分优先级。词频越高,词被切分出来的可能性就越大。
- 词性:这是词的词性,如名词(n)、动词(v)等。这个字段是可选的,如果不提供,jieba 会自动推断词的词性。
在给出的例子中,"李小福 2 nr"表示"李小福"是一个词,它的词频是 2,词性是 nr(人名)。这意味着在进行分词时,“李小福"会被优先考虑作为一个整体进行切分,而不是被切分成"李”、"小"和"福"三个词。
自主训练模型
如果上述的都不能满足我们对中文解析的处理,我们可以自己训练模型,安装 TensorFlow 然后自己需训练模型,这儿我就不展开赘述了。
TensorFlow 是一个开源的机器学习框架,由 Google 开发和维护。它提供了一个灵活的平台,用于构建和训练各种机器学习模型,包括神经网络。TensorFlow 最初是为了支持深度学习任务而设计的,但它也可以用于其他类型的机器学习任务。
1 | from transformers import pipeline |
可以导入不同的模型
模型地址
怎么匹配问题?
我对客户的问题进行了分析,但是我应该怎么才能最好的匹配到我事先准备好的问答库上呢?
要将客户的问题匹配到预先准备好的问答库,可以使用以下几种方法:
-
基于关键词的匹配:可以提取问题中的关键词,然后在问答库中查找包含这些关键词的问题。这种方法简单易实现,但可能无法处理复杂的问题。
-
基于向量空间模型的匹配:可以将问题和问答库中的问题都转换为向量,然后计算问题向量之间的相似度。可以使用 TF-IDF、word2vec、BERT 等方法来将问题转换为向量。这种方法可以处理更复杂的问题,但需要更多的计算资源。
-
基于深度学习的匹配:可以使用深度学习模型来匹配问题。例如,可以使用 Siamese 网络或 Transformer 网络来计算问题之间的相似度。这种方法可以获得最好的匹配效果,但需要大量的数据和计算资源。
在实际应用中,可能需要根据需求和资源来选择合适的方法。例如,如果问答库很大,可能需要使用更快的匹配方法。如果问题很复杂,可能需要使用更准确的匹配方法。
好的,我们不需要知道这儿到底是什么做的,因为 AI 客服本身就是一个不简单的项目,如果真的要去做,我们分配到不同的团队,将各个的问题剖析,拿出解决方案。
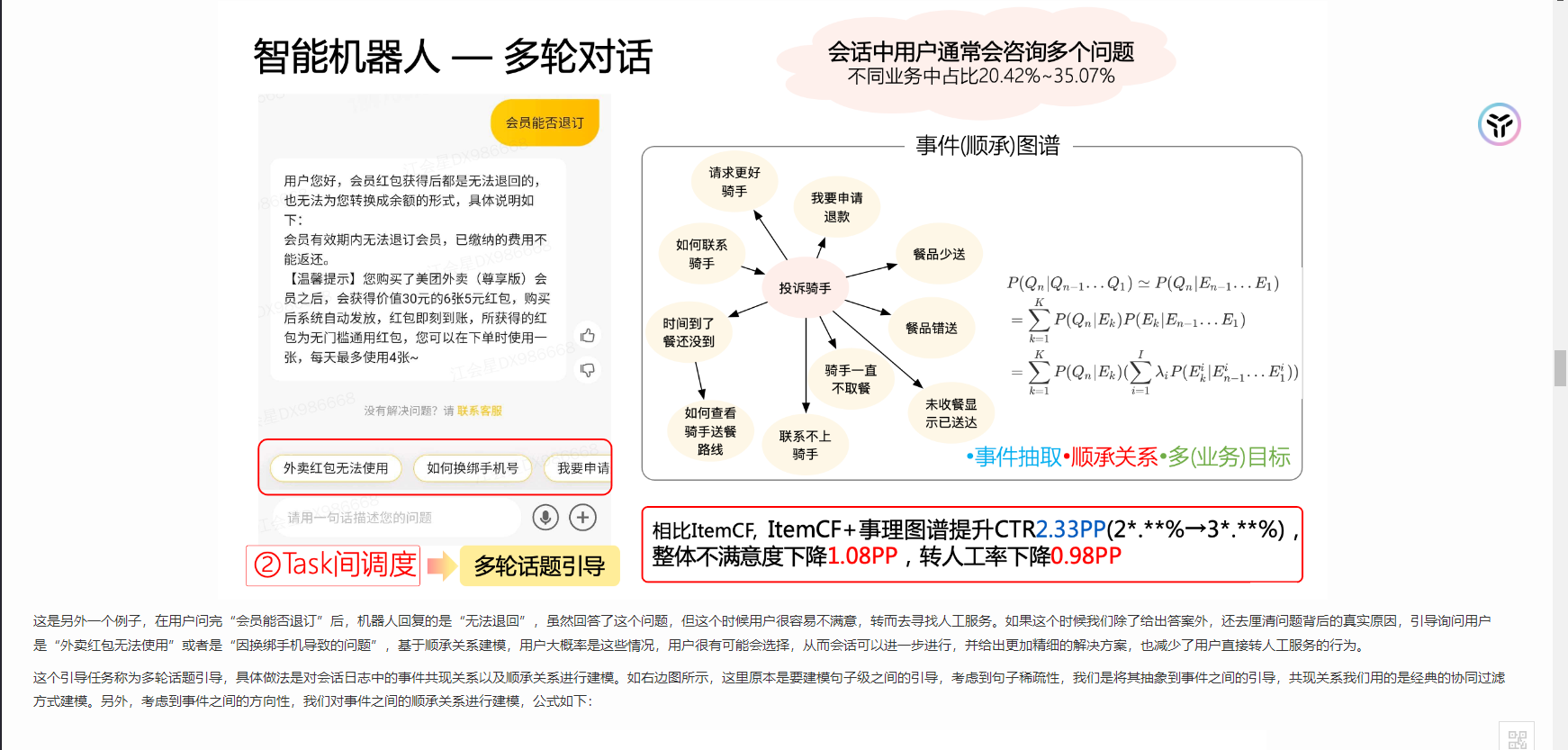
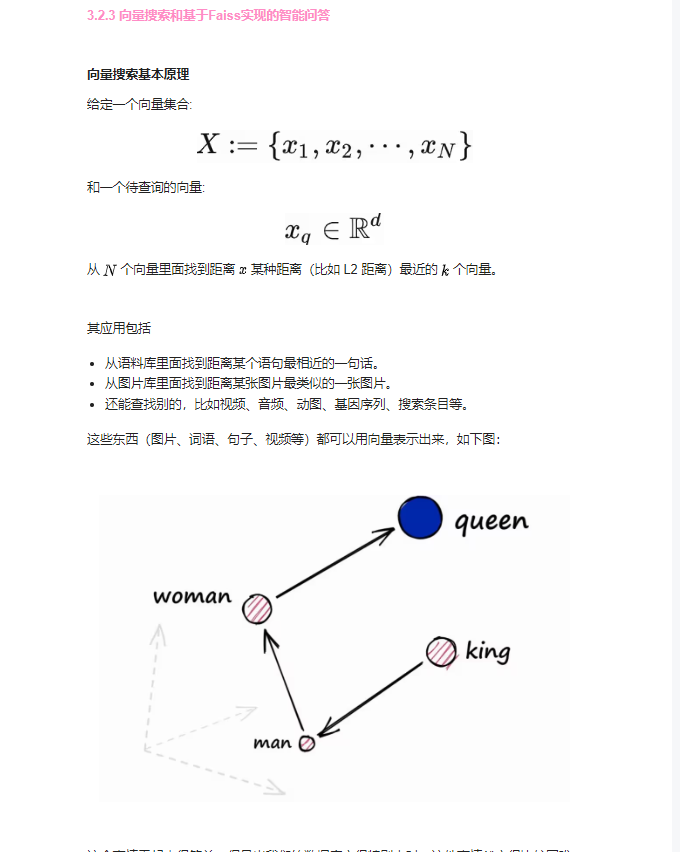
我将美团和哔哩哔哩的搜索贴图放在这儿感兴趣的可以去研究一下:
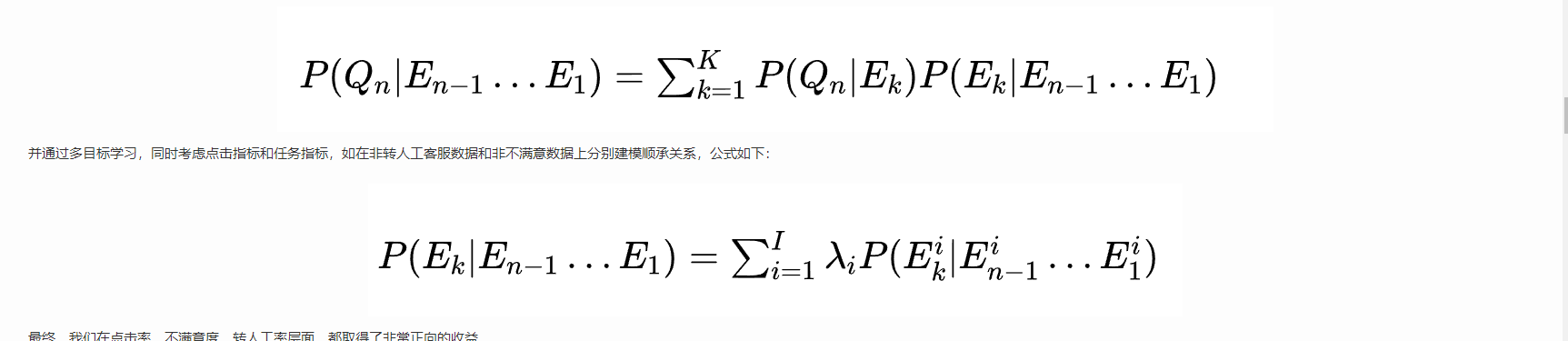
怎么生成回答?
生成回答这个问题需要看需求是怎么样的,也要看搜索算法的匹配度,如果高度匹配直接返回回答,如果不是可以选择是否重新生成反问。
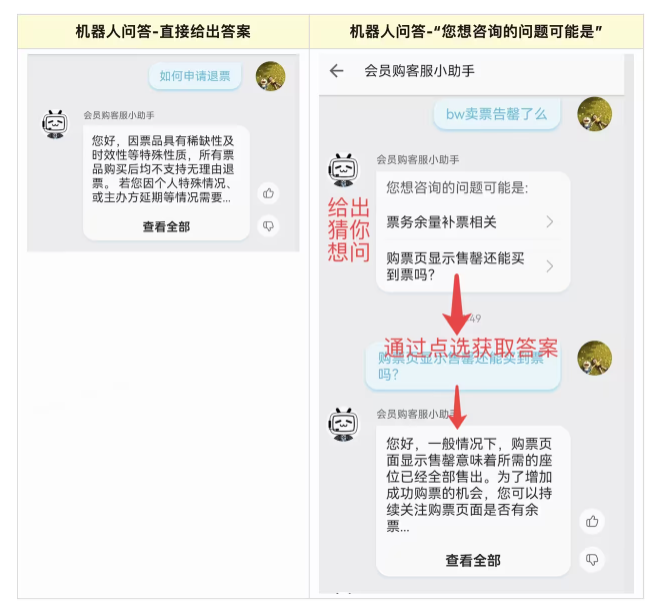
如果客服的提问,是需要某个功能,比如联系骑手,那么就需要返回某个动作。这儿就会涉及到动作的定义。
相关资料
文章推荐
- 标题: 怎么实现一个人工智能 AI 客服
- 作者: 兰涛
- 创建于 : 2024-01-04 09:38:00
- 更新于 : 2024-03-08 13:41:39
- 链接: https://lands.work/20240104/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。