
Flow2Spec:让 AI 不再每次从零认识你
你的 AI 是不是也「失忆」了?
新开一个 Cursor 会话,它不记得上一轮讨论过的表结构。
换一台电脑,Claude 不知道你们团队约定的错误码和 Redis 锁 key。
模型可能还是同一个,但上下文断了——表现就会时好时坏。
于是你开始重复劳动:
- 每轮重新交代「评价模板库在哪、批量重评分是异步还是同步」
- 看着 AI 在全仓 grep,翻几百个接口才敢动手
- 改完代码,文档没人更新;下次会话,AI 又从源码「猜」约束
这不是模型不够聪明,是喂给它的料不对。
同一句话,两种体验
需求只有一句:
改一下评价模板文案库的批量重评分
没有项目记忆时,对话往往变成:
1 | AI:这个模块的表在哪? |
有 Flow2Spec 时,更像这样:
1 | [matcher 命中] 评价模板库相关主题 |
差别不在「模型突然变强」,而在上下文变准了:几 MB 的仓库,一次只读几百行该读的硬约束。
Flow2Spec 是什么?
Flow2Spec 是一个可 npx 初始化的开源方案,核心概念叫 Memory Coding(记忆编码):
把必须长期记住的东西,编码进可提交的仓库——可 diff、可 PR、可 review、可协作。
不押在模型私有 Memory 里,也不靠全仓向量「概率猜」。
在仓库里,它用 四环 托住长期上下文(别把它简化成「又一个知识库」):
| 环 | 落在哪里 | 解决什么 |
|---|---|---|
| 知识环 | .Knowledge/ |
路由、主题、存量/需求文档 |
| 任务环 | .task/ |
跨会话续作清单、用户代办 |
| 规则环 | rules / AGENTS.md |
规定 AI 怎么读、怎么做 |
| 技能环 | f2s-* 技能 |
维护知识、触发流程 |
Memory Coding:仓内四环
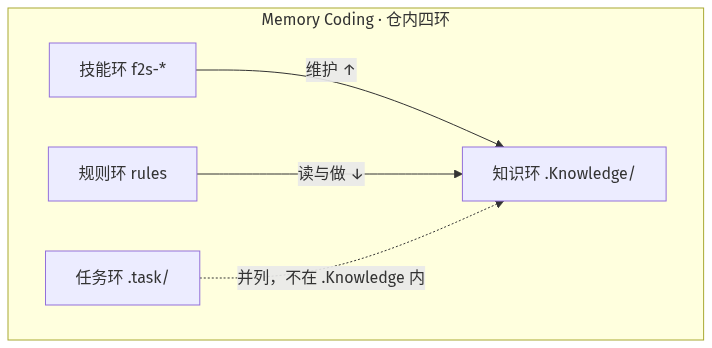
技能环维护知识环,规则环规定如何读取与执行;任务环与 .Knowledge/ 并列于仓内,同属 Memory Coding。
日常可以记三件事:
- 跨设备、跨会话记住项目上下文
- 用机读路由清单收窄阅读面,不让 AI 翻遍整个仓库
- 改代码时顺手更新知识(
f2s-kb-feat/f2s-kb-fix等),减少文档与实现分家
架构与流程设计
知识层 vs 执行层
业务知识落在 .Knowledge/,各 IDE 的规则与技能落在配置根(Cursor / Claude / Codex 各自原生加载),二者一起喂给 AI:

知识环:横读收窄 + 纵链叠层
知识环内部不是扁平 Markdown 堆,而是 L0→L3 横读 与 topicDependencies 纵链 组合:
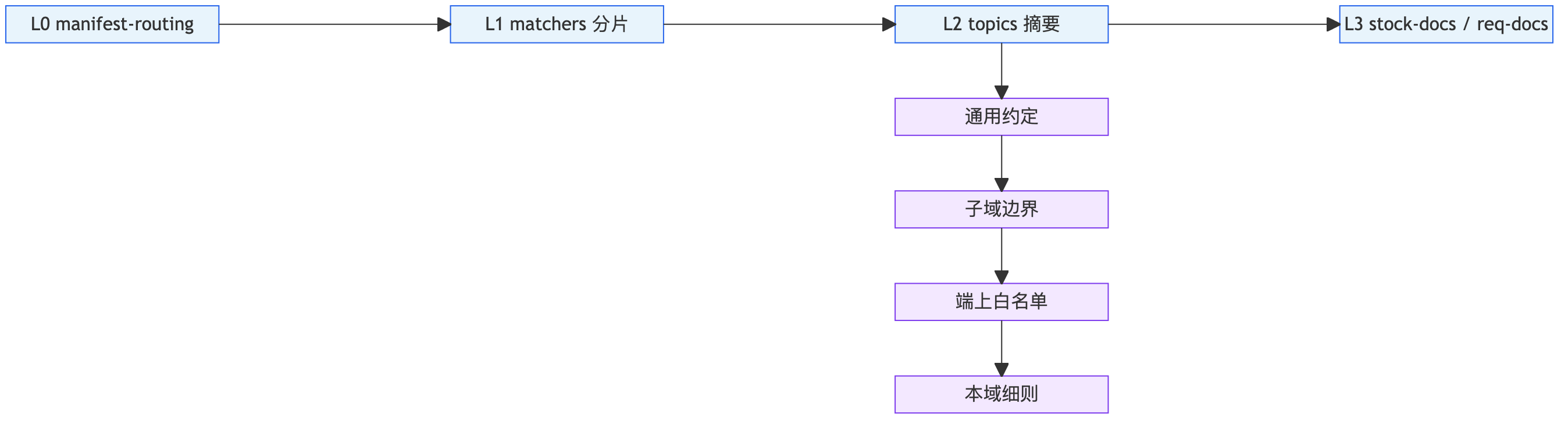
| 层级 | 路径 | 作用 |
|---|---|---|
| L0 | manifest-routing.json |
机读路由、依赖声明 |
| L1 | matchers/*.json |
关键词命中,match 只读一片 |
| L2 | topics/*.md |
硬约束摘要;expand 拉依赖 |
| L3 | stock-docs/、req-docs/ |
长文档,按需下钻 |
渐进式路由:match → expand → verify → act
用户说一句话,框架按流程收窄上下文,而不是全仓 grep:

- match:读
manifest-routing.json,按关键词打开一个 matcher 分片 - expand:按
topicDependencies自动拉齐依赖主题 - verify:缺口不够就向人澄清,不静默瞎猜
- act:置信度够了才改代码
可以记一句:不是让 AI 更聪明,是把噪声切掉。
真实业务仓库跑过三个月的量级(来自项目公开数据):
| 指标 | 数值 |
|---|---|
| 对外接口 | 416 |
| 源码 | ~796 文件 / 4.7 MB / 约 10 万行 |
| Flow2Spec 单次典型加载 | ≈ 300 行 topic |
技能维护闭环
改代码、写文档、提交、合并——多条 f2s-* 入口最终都汇聚到 .Knowledge/,驱动下一轮 AI 会话:
七条入口 · f2s-git-commit 在提交时做知识覆盖检查 · .Knowledge/ 是唯一汇聚点。
跨会话任务续作
.task/ 记录 checklist 与 linkedSkill;新会话首条消息命中关键词即可续作,无需重新交代上下文:

一分钟上手
1 | npx @double-codeing/flow2spec@latest init |
会生成空骨架:目录结构 + 路由配置 + 多端规则入口。不必先写完全部文档——下次需求命中哪块,再补哪块 topic。
想先「看感觉」再 init,可以打开在线演示(13 页 HTML PPT,键盘 ← → 翻页,S 演讲者模式):
更细的命令与技能链见仓库文档:使用说明 、命令速查 、设计说明(含更多流程图) 。
和「别家方案」差在哪?(诚实选型)
Flow2Spec 不是新的 IDE,也不是新的 Agent,而是补齐「已有工具连接处」的空缺:
| 常见路线 | 强项 | 和 Flow2Spec 的分工 |
|---|---|---|
| OpenSpec 等 spec 工具 | 格式严谨、人读友好 | 偏单向;代码漂移后不易反哺知识库 |
| 技能仓 / Cursor Rules 合集 | 即插即用 | 缺项目级机读知识,换 IDE 要重来 |
| RAG / 向量库 | 全仓可搜 | 概率命中;错误码、锁 key 等硬约束易拿错 |
| Spec Kit / BMAD 类 | 从 0 到 1 快 | 二次迭代容易 spec 与 code 分家 |
| 模型自带 Memory | 省得自我介绍 | 难团队共享、难版本化、难 review |
Flow2Spec 更擅长:从 1 到 N 的持续迭代——知识在 Git 里演进,技能在改代码时维护知识,任务在 .task/ 里留痕。
一句老实话:停用 f2s-* 维护技能,知识库照样会腐化。
差别在于:腐化时会被缺口闸门喊出来,而不是静默跑偏。
什么时候别用?(省你时间)
- 一次性脚本:写完就删,丢几段 Markdown 给 AI 更快
- 单人极小项目:一份
CLAUDE.md可能就够了 - 团队不愿把
.Knowledge/当代码一起维护:工具替代不了协作纪律
若你是多模块、长周期、多人/多端 AI 协作的业务仓库,收益通常明显大于 init 成本。
适合谁?
- 用 Cursor / Claude Code / Codex 写业务代码,且厌倦每轮重复交代
- 希望错误码、锁、上限、白名单等硬约束进仓库、可 review
- 需要 B 端 / C 端 / 接口端多仓 在同一套知识方法论下推进
- 想要「改功能 = 更新知识」的闭环,而不是「文档另起炉灶」
结语:给 AI 一张不会丢的「项目地图」
大模型会继续升级,但会话仍会结束、设备仍会换、同事仍会交接。
把记忆写进 Git,让 matcher 带你读到该读的那 300 行,用 f2s-* 在改代码时顺手记账——这是 Flow2Spec 想帮你建立的习惯。
下一步建议:
- 打开 在线演示 花 10 分钟过一遍 Before/After
- 在一个真实业务仓执行
npx @double-codeing/flow2spec@latest init - 选最近最常改的一个模块,用
f2s-doc-add或手写第一个 topic,感受 matcher 命中
仓库:https://github.com/lands-1203/Flow2Spec · 协议 MIT
- 标题: Flow2Spec:让 AI 不再每次从零认识你
- 作者: 兰涛
- 创建于 : 2026-05-19 10:00:00
- 更新于 : 2026-05-19 13:53:07
- 链接: https://lands.work/f2s20260519/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。